We're excited to announce that we have begun to make a portion of our codebase available as open source. This is just the beginning. We plan to release much more in the future.
We proudly recognize Dr. Li for her exceptional contributions to our Probabilistic Vaccine Effectiveness model debugging, testing and analysis, Risk Factor module testing, and Uncertainty module code.
We commend Ms. Ramirez-Herrera for her steadfast dedication, hard work, and strong leadership of the Epidemiology team, culminating in a successful poster presentation.
COVID-19 continues to affect countries around the world, and while the accelerating distribution of vaccines is much welcomed news, it will be many months before enough people are vaccinated to achieve herd immunity. New COVID-19 variants present a continuing threat. In the meantime, we still need a data-driven, scientifically sound way to quantify the risks of infection and reduce its spread.
In the future, Pandemonium's app and also its framework can be applied to new pandemics and outbreaks.
Pandemonium's risk app and framework differ from other risk apps. Pandemonium is:
While the app appears very simple to the user, it has a sophisticated Stochastic Heterogeneous Hybrid Spatially-Hierarchical/Dynamic and Demographically-structured Regional Susceptible-Exposed-Infectious-Recovered-Dead (SEIRD) Compartmental model built on the Pyro Probabilistic Programming Language (PPL), using Markov Chain Monte Carlo (MCMC) and other statistical inference techniques.
We are excited to announce the launch of an update
to our Pandemonium Personal Risk Assessment app for testing with a limited feature set,
which will be expanded on a rolling basis.
We hope to use this phase of testing to receive user feedback, resolve issues promptly and make improvements before we scale up further.
We welcome those interested in being a tester to
sign up here.
We are raising funds to be able to refine and expand Pandemonium. We count on your generosity to help us scale up. We also need more volunteers with various skills, including non-technical, like legal, marketing, etc., as well as access to more data.
The IRS has determined that we are tax-exempt non-profit organization under section 501(c)(3) of the IRS tax code. Please, make a tax-deductible donation if you can to help us in our mission!
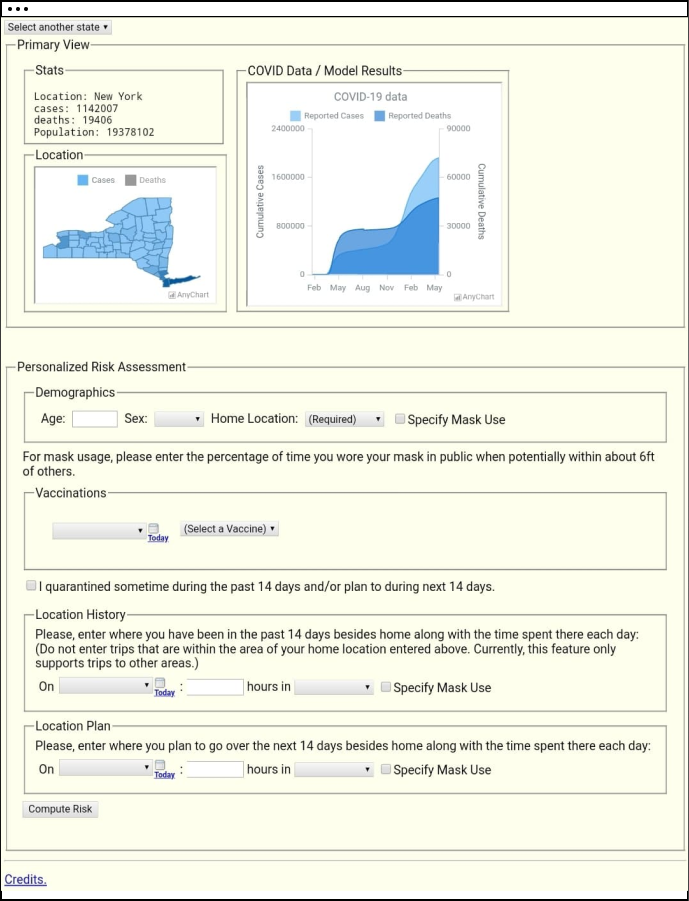
Our risk app's interface allows users to input to
input demographic and personal metrics such as age, sex, location, and vaccination status and dates. It also uses behavioral metrics such as mask usage, location history, quarantine periods and planned travel.
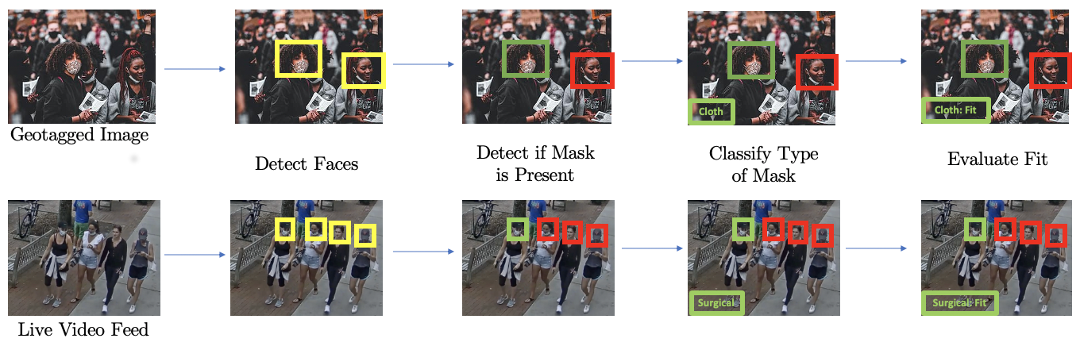
One of our sub-projects involves detecting the percentage of people wearing face masks of each type from publicly posted geo-tagged photos to better estimate the face mask usage in each location and at each point in time to be fed into our epidemiological model. Shruthi Ravichandran, one of the very talented Research Science Institute (RSI) students we mentored, developed a machine learning model for us in 2020 as described in her RSI paper. Subsequent work on this sub-project has been focused on mitigating the inherent sampling bias that results from using publicly posted photos.
Follow Us